Plot Digitizer - Produce Random Synthetic Images
I. Objectives
To build a generalized model for extracting accurate digits from plots, like line plots, dot-line plots, scatters, vertical and horizontal plots and of course pie charts, etc. Here are some examples.
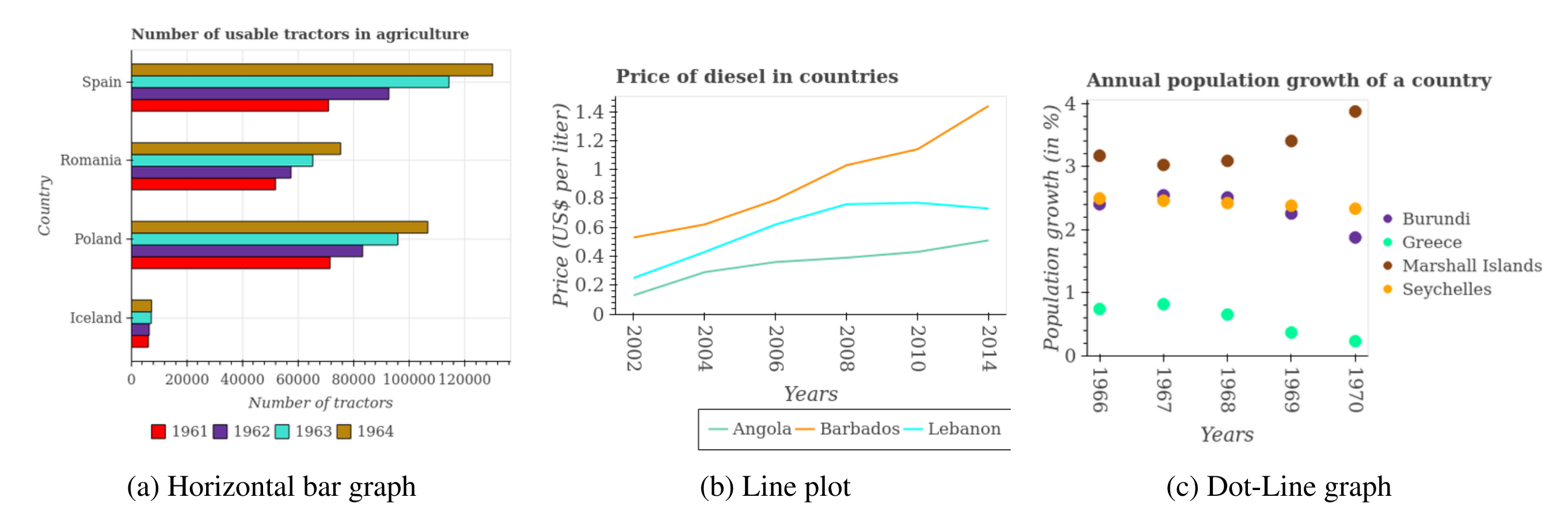 Sample plots of different types
Sample plots of different types
In this work, we intend to solve this problem in a sequence-based manner. That is to say, based on deformable detection transformer (DETR) and other important query-based methods, the input images will be converted into sequential digits with variable length. Yet it is still too soon to get into details. As for this first log, we mainly focus on how to produce random sythetic plots for our dataset.
II. Draw by Matplotlib
First we try to accomplish three different typical types: bar, scatter and dot-line. We here introduce matplotlib for random drawing.
1
from matplotlib import pyplot as plt
We don’t want to give too much pressure on our first test model. Therefore all our images are set into a fixed size via:
1
plt.rcParams['figure.figsize'] = (5, 5)
Thus the plots’ general appearance are unified and all in a matplotlib style. Later we will try to introduce a public dataset, like FigureQA, to boost the generalization ability. But today we just want to know if it’s work at all.
bar plot
1 2 3 4 5 6 7 8
bar_count = np.random.randint(2, 10) x = np.linspace(0, 1, bar_count) y = np.random.random(bar_count) plt.figure() plt.bar(x, y, width=1/bar_count) plt.close()
scatter plot
1 2 3 4 5 6 7 8 9 10 11
scatter_counts = np.random.randint(9, 15) x = np.random.random(scatter_counts) y = np.random.random(scatter_counts) plt.figure() plt.xlim(0, 1) plt.ylim(0, 1) colors = np.random.rand(scatter_counts) plt.scatter(x, y, s=80, c=colors, alpha=1) plt.close()
dot-line plot
1 2 3 4 5 6 7 8 9 10
keypoint_counts = np.random.randint(3, 10) x = np.linspace(0.1, 0.9, keypoint_counts) y = np.random.random(keypoint_counts) plt.figure() plt.xlim(0, 1) plt.ylim(0, 1) plt.plot(x, y, marker="*", ms=10, linewidth=4.0, mfc="4CAF50", alpha=0.6) plt.close()
The so-called digits from the plot is composed by several keypoints which consist of x, y representing the x-, y- axis value in percentage (0 ~ 1, so far it is enough). Considering it is genrally a continuous variable on x-aixs in dot-line plot and scatters, we adopted ply.xlim to take all part of x-axis into use. If we got a real value of start-point and end-point on x-, y-axis, it would be easy for us to directly translate the percentage value into some real content in the real world. But in the bar plot, it is discrete on x-axis. Only the predicted y percentage-value matters here actually. A much more sophisticated reasoning on x-axis and plot-legend will be needed at the end.
The number of keypoints equals to the final predicted sequnence’s length, it is variable and defined by _counts.
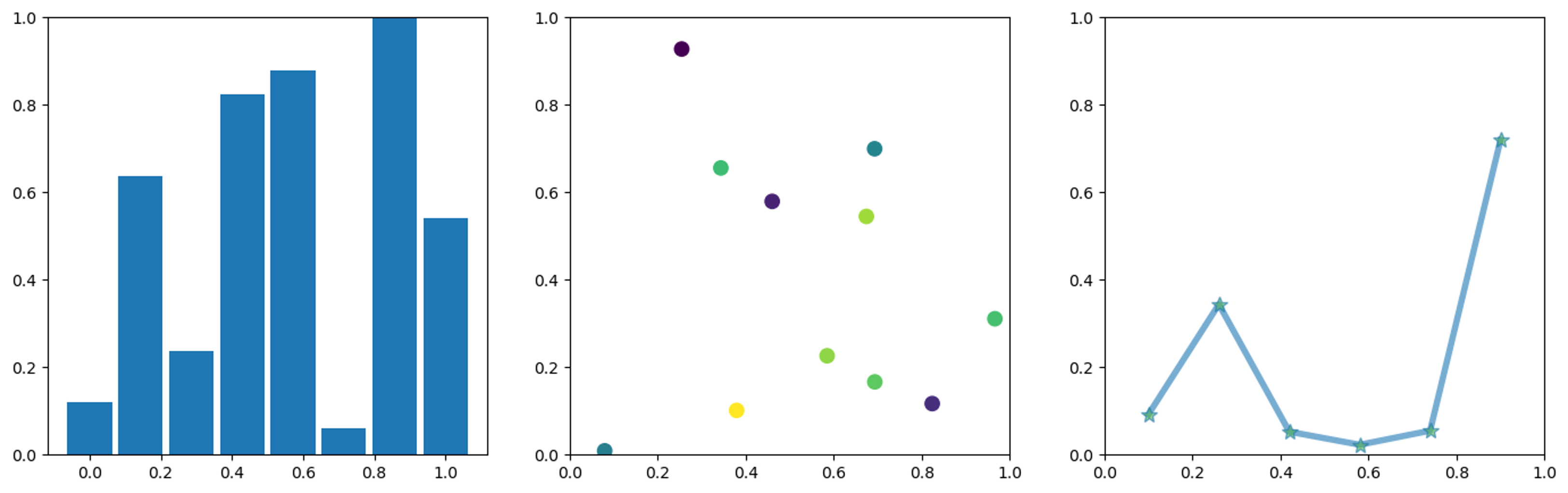 bar, scatters and dot-line
bar, scatters and dot-line
Ok, so we can produce random synthetic images now. They are all unified into similiar form and style. It is not perfect but enough for our start test. Let’s put them into the sub-class of Dataset from torch then.
III. Dataset Class
a. DataLoader Introduction
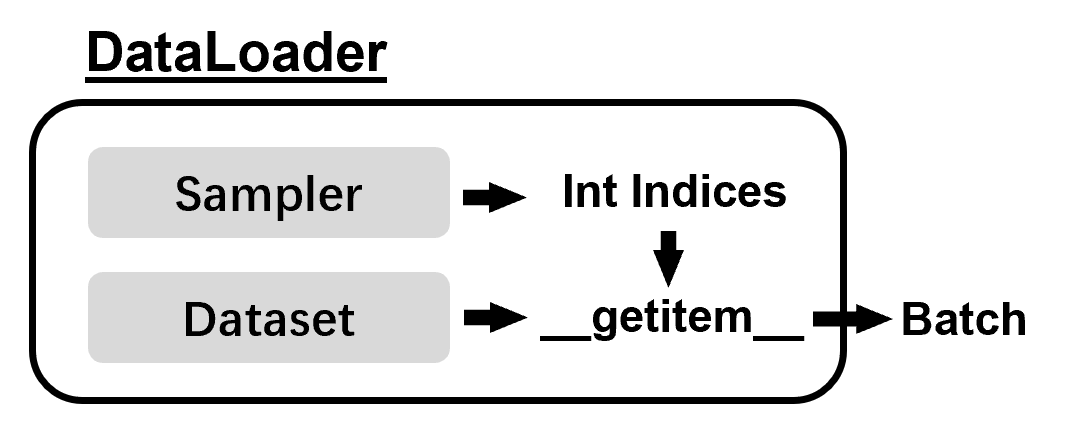
We need a customized Dataset sub-class for our data object.
All dataset that represent a map from keys to data samples should subclass it. All subclasses should overwrite
__getitem__(), supporting fetching a data sample for a given key. Subclasses could also optionally overwrite__len__(), which is expected to return the size of the dataset by manySamplerimplementations and the default options ofDataLoader.
1
2
3
4
5
6
7
8
9
10
class DataLoader(object):
...
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter)
batch = self.collate_fn([self.dataset[i] for i in indices])
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
This is a part of source code from DataLoader.__next__:
- DataLoader by default constructs an index sampler to yields these integer indices (iterable, thus can fetch via
next) which were later used to fetch class instances from Dataset subclass. __getitem__makes it possible to fetch class instancelike it was a list, which is an built-in python function and defined in subclass.- Everytime from
dataset[idx]we can only get one single sample, normally it returns a tuple which includes a pair of image and label or bbox. The output has to be reorganized bycollate_fnin batch style. - Finally, pass the batch data of this iteration from CPU to GPU via
pin_memory_batch.
Thus, what we have to do here is to build a customized Dataset sub-class and define the function, __getitem__ and collate_fn, as needed.
By the way, that is an old version of DataLoader from torch and we only select the section when the num_works was set to zero. It is easy to illustrate from that way. And the code from newest stable version (1.13.0) is like:
1
2
3
4
5
6
7
8
9
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
...
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
return data
b. Generate Data Item
1
2
3
def __getitem__(self, index):
seed = index + self.start_seed
np.random.seed(seed)
Index corresponds to the indice we got from sampler and enables us to instantiate an exclusive data sample. By combining it with our original seed value, we got a random different seed every time which means plots with different appearance.
1
2
3
bbox = np.concatenate([
x[:, None], y[:, None], np.zeros((x.shape[0], 1)), np.zeros((x.shape[0], 1))
], aixs=1)
As it mentioned before, we summerized the plot by numerous keypoints, with x- and y-axis value. Yet here we not only include the keypoint axis value but also a weight and height for bbox. It is natural because our inspiration is from general query-based object detection algorithm. We leave it to be temporarily. It has nothing to do with the training yet since we set them all into zero and L1 loss only conduct on coordinates. But later, we will have some adjustment on it to introduce some geometrical constraint into this format and dilate the general unit of these keypoints.
A Memory Leakage
Some unexpected issue happened here when we were trying to turn our PILImage into Tensor: (Version: Python - 3.6.5, Numpy - 1.19.5, Torch - 1.10.1)
1
2
PILImage = Image.open(buff).convert('RGB').resize((480, 480))
TensorImage = ToTensor()(PILImage) # memory leakage
 Memory Leakage on ToTensor
Memory Leakage on ToTensor
A memory leakage happened here. Because of this, the memory usage rapidly piled up and soon shut down automatically. Memory Profile was used here to seek the leak point. It is quite powerful. It shows that every time when the ToTensor() were used, it spare out some additional space in memory and can not be automatically released after the reference count back to zero, or what we say, finished (I’m a starter on python’s garabage collection mechanism).
We later go to the detail of class ToTensor:
Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1) or if the numpy.ndarray has dtype = np.uint8
According to that, we reimplement the transformation trying to find where the leakage exactly happened.
1
2
3
4
img_arr = PILImage.astype(np.float32)
img_arr = img_arr / 255. # memory leakage
img_arr = torch.from_numpy(img_arr)
img_arr = img_arr.permute(2, 0, 1)
 Memory Leakage during Calculation on array
Memory Leakage during Calculation on array
It is nature for numpy. Yet what we expect, automatically memory release after that, never happened. We even tried to manually release it via gc.collect() but turned out to be useless. Till then, we still don’t know why. Therefore, we implemented it in a multiprocessing style at the end.
1
2
3
4
def __getitem__(self, index):
seed = index + self.start_seed
with Pool(1) as p:
return p.apply(self._generate_dataset, [seed])
The plot sample will be generated and transformed to Tensor in _generate_dataset, and the memory will be automatically released after the process were terminated. It works but costs more time for training.
You may encounter following errors for conducting multiprocess here, a detailed discussion on python multiprocessing and apply(), map() function is present in my another post where you can find solutions.
TypeError:
run()arguement after * must be an iterable, not int
ValueError: not enough values to unpack (expected *, got 1)
Finally, return the TensorImage and corresponding bbox (keypoints coordinates) and get our dataset sample.
c. Convert Image Metas
When automatic batching is enabled,
collate_fnis called with a list of data samples at each time. It is expected to collate the input samples into a batch for yielding from the data loader iterator. The rest of this section describes the behavior of the default collate_fn (default_collate()).For instance, if each data sample consists of a 3-channel image and an integral class label, i.e., each element of the dataset returns a tuple
(image, class_index), the defaultcollate_fncollates a list of such tuples into a single tuple of a batched image tensor and a batched class label Tensor. In particular, the defaultcollate_fnhas the following properties:
It always prepends a new dimension as the batch dimension.
It automatically converts NumPy arrays and Python numerical values into PyTorch Tensors.
It preserves the data structure, e.g., if each sample is a dictionary, it outputs a dictionary with the same set of keys but batched Tensors as values (or lists if the values can not be converted into Tensors). Same for
lists,tuples,namedtuples, etc.
default_collate() would not be enough for this work.
Firstly, turning multiple dataset tuples, (TensorImage, bbox), into batch and transform it into torch.Tensor is necessary. Taking a batch of multiple dataset samples as input:
1
batch = self.collate_fn([self.dataset[i] for i in indices]) # old DataLoader
Reschedule it via zip(*), and formulate a tensor image batch:
1
2
TensorImages, bboxes = [*zip(*batch)] # or via `list(zip(*batch))`
TensorImgBatch = torch.concat([_.unsqueeze(0) for _ in TensorImages])
 Unzip a Tuple Set
Unzip a Tuple Set
Secondly, we need conduct some additional process on bbox information, convert it into metas that includes text query for decode. As mentioned before, every plot is formed by a sequence of keypoints with a variable length. Calculate the maximum of this length within a batch:
1
max_seq_length = max([b.shape[0] for b in bboxes]) + 2 # 2 for additional maskers on start "<SOS>" and end "<EOS>" of a sequence.
Pad with zero on empty blocks, and output an mask on this data:
1
2
3
4
5
b_padded = np.zeros((max_seq_length, 4)) # 4 for (x, y, w, h) and it is zero on w and h
b_padded[1:b.shape[0]+1] = b
b_mask = np.zeros(max_seq_length)
b_mask[1:b.shape[0]+1] = 1
Again, here the bbox is nothing similar to an actual bounding box, it’s just for convenience and w and h are all ignored. We are just trying to solve the problem as an Object Detection and based on query-based methods. And the meta information for every plot sample was like:
1
2
3
4
5
6
7
8
9
img_metas.append(
{
...
'text': ','.join(["<SOS>"]+["<thead>"]*b.shape[0]+["<EOS>"]+["<PAD>"]*(max_seq_length-b.shape[0]-2)),
'bbox': b_padded,
'bbox_masks': b_mask
}
)
Finally, we got all we need: random synthetic plots TensorImgBatch, each of them is made up by a sequence of keypoints, and corresponding meta informations img_metas for decoder which consist of ground-truth, query text and mask. That’s the whole objective for this post.